Hace una semana leí el post de la milestone 5 de Spring MVC 5.0 y viendo los avances que habían hecho desde mi última prueba de las nuevas características reactivas, decidí aventurarme de nuevo a echar un ojo a ver que nos preparan para las siguientes versiones. Esta vez escogí Spring Boot 2.0 (SNAPSHOT) que será el encargado de incluir en el proyecto Spring Boot las características de Spring WebFlux que es como han llamado a esta nueva parte reactiva de Spring.
Sin complicarme demasiado y dejando a un lado la originalidad, mi objetivo era crear un CRUD sobre tareas asignadas a un equipo. Con esto me ha bastado para explorar no solo la capa de routing (@RestController, @GetMapping, etc..) sino también he indagado un poco como funcionará Spring en su capa de persistencia con Spring Data 2.0-Kay.
Spring WebFlux
Mientras que a nivel de código (que explicaré más adelante) y por la abstracción que proporciona Spring (aka Magia Negra) apenas encontramos diferencias. La realidad es que tienen una orientación completamente distinta. Spring WebFlux está orientado al uso de contenedores de aplicaciones no bloqueantes (Netty en mi caso). Estos contenedores funcionan con un loop de eventos sin bloquear nunca la entrada/salida y sirviendo de manera asíncrona.
Al declarar un controlador podremos seguir usando la anotación “@RestController” que se comportará como siempre. Por supuesto dentro de un controlador incluiremos las rutas como métodos usando la anotación de método “@GetMapping” que a diferencia del mapeo clásico, por defecto produce un event-stream como respuesta del Content-type del http.
|
|
Lo destacable de este controlador es que devuelve un Flux. Al devolver un flux de Task y con el Content-Type como “text/event-stream” lo que hacemos es enviar de manera asíncrona como datos en un stream las tareas que hay al navegador. Que las recibe como Server-sent Events y deja un canal abierto de una sola dirección entre servidor y cliente.
Este Stream de datos abierto nos permite realizar operaciones de manera asíncrona e ir informando al cliente del estado. Por ejemplo, para la creación de una nueva tarea lo que hago es devolver un Flux de OperationStatus un enumerado que incluye Start, Complete y Error, de esta manera cuando se recibe la petición se crea un flux en el que se publica un OperationStatus que es Start y de manera asíncrona se gestiona el resto de la lógica de creación.
|
|
La búsqueda del equipo es también asíncrona ya que se usa un repositorio reactivo de mongodb, debemos declarar la búsqueda y subscribirnos al Mono que nos devuelve y esperar recibir el equipo. Cuando recibimos el equipo llamamos a un servicio para guardar la nueva tarea que es tambien asíncrono y debemos suscribirnos para gestionar que se guarde la tarea o que ocurra un error. Todo esto se incluye dentro de un FluxSink que nos permite ir emitiendo estados “en caliente” y mantener el contexto.
Cuando una nueva tarea es creada, si alguien ha llamado al primer endpoint que puse del controlador para subscribirse a todas las tareas. Automáticamente la nueva tarea es publicada en el stream de datos entre el servidor y el cliente. Obtenemos un push de las nuevas entidades directamente al cliente.
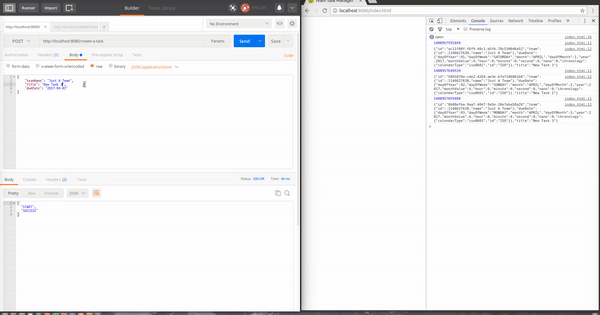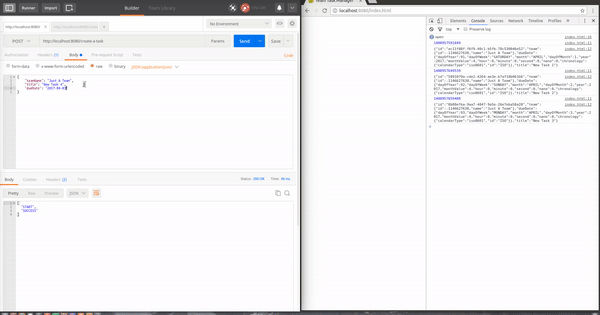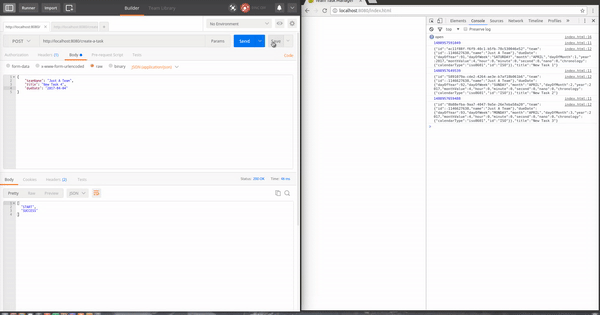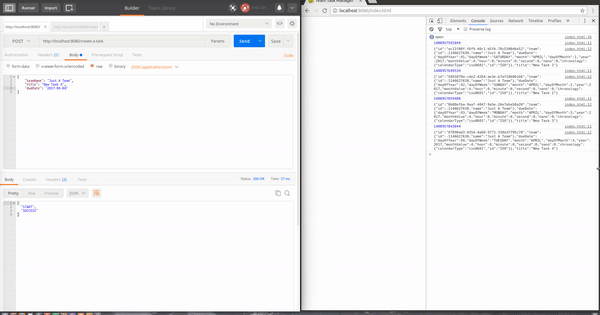
El postman envia una petición para crear la nueva tarea al servidor y este la procesa y la guarda. Una vez guardada la tarea entre el repositorio de MongoDB de Spring Data y Spring WebFlux hacen la magia por nosotros y después de mapear el objeto este se envía al navegador.
Lecturas y escrituras reactivas (Spring Data)
Spring nos da otra capa de abstracción sobre los datos para poder comunicarnos de manera asíncrona y reactiva con la base de datos, en mi caso he elegido Spring Data MongoDB.
Lecturas
Para leer un registro tenemos los típicos métodos de Spring Data, con una diferencia, devuelven tipos reactivos que son lazy y tienes que suscribirte para que la operación se efectiva. Para encontrar el equipo por nombre, lo que hago es un “findAll” y luego aplico un filtro para quedarme solo con los que son del mismo nombre. El Flux resultante lo convierto en un Mono al que desde fuera me suscribo para crear la tarea cuando reciba la respuesta.
|
|
Nota: Podría usar findOneByName(String name) que también devolvería un Mono pero quería hacer un ejemplo concatenando operaciones.
Para leer todas las tareas y mantener un stream continuo desde el servidor al cliente hay que hacer algo más, no mucho, esto es Spring hacer algo normalmente es añadir una anotación y por supuesto en este caso no decepciona. Para crear un método de lectura que con cada nueva escritura publique un nuevo dato en nuestro stream de datos de lectura abierto, tenemos que crear un método find que use un tailable cursor sobre una capped collection, es decir, añadir la anotación “@InfiniteStream” en un método en la interfaz.
|
|
Esto nos permite que el servicio de lectura solo tenga que ejecutar la query y hacer un mapeo sobre el flux resultante:
|
|
Escrituras
La escritura más compleja es crear una nueva tarea, como comenté antes tiene que ser una capped collection. Entonces al escribir una nueva tarea si la colección no existe, tenemos que tener consideración de crearla con esas características.
|
|
Al crear una nueva tarea si no existe la colección lo que hacemos es crearla de manera bloqueante y con las características que necesitamos para luego invocar al save sobre la nueva tarea.
El resto de escrituras son más sencillas. Por ejemplo, para crear un equipo nos basta con llamar al método save del repositorio de Spring Data y subscribirnos al Mono que devuelve. Aunque no vayamos a hacer nada con el resultado es obligatorio suscribirse para que se ejecute la operación.
|
|
Conclusión
Mi impresión general ahora mismo es positiva, como siempre todo lo relacionado con los framework hay que conocerlo y usarlo con cautela para que no te atrape su magia negra. Lo que más me ha gustado ha sido el poder usar de forma tan cómoda los Server-sent Events y lo que eso implica con los tipos reactivos para poder tener un stream de datos desde el servidor al cliente.
Siendo Spring el framework web de java más usado, espero que podamos usar estas features para crear un impacto positivo importante en la experiencia de usuario de las aplicaciones sin apenas invertir en tecnología y desarrollo.
Repositorio con la aplicación completa